Un approccio IaC con Cloud Development KIT (CDK)

Un esempio di progetto di Cloud Development Kit (CDK) in TypeScript, che permetta di creare un’infrastruttura completa di Network, EC2, RDS, CloudFront, backup e monitoring.
Come discusso nell’articolo precedente “INFRASTRUCTURE AS CODE (IAC): COS’È?”, Cloud Development Kit è una delle scelte tecnologiche possibili quando si decide di utilizzare un approccio di Infrastructure As Code per una infrastruttura AWS.
In questo caso approfondiremo un esempio di progetto, che permetta di realizzare una infrastruttura completa e pronta all’uso.
Presupponendo che l’utente abbia configurato il proprio PC con le proprie credenziali AWS, si può installare prima NodeJS e poi CDK tramite pacchetto npm.
Se dovessero servire indicazioni aggiuntive, si può fare riferimento alla documentazione ufficiale: https://docs.aws.amazon.com/cdk/v2/guide/getting_started.html.
Per ricevere il codice realizzato per questo articolo compilando il form a questo link, oppure puoi partire da una cartella vuota e seguire passo passo per ottenere un progetto completo.
Come creare il progetto
Partendo da zero, create una nuova cartella e datele un nome a vostro piacimento.
Cloud Development Kit permette di sviluppare con vari linguaggi, in questo caso useremo TypeScript, quindi all’interno della cartella aprite un terminale e lanciate il seguente comando: cdk init app –language typescript per inizializzare il progetto.
A questo punto avrete una cartella popolata con vari file, nella root ad esempio troviamo i comuni README.md e package.json tipici di un progetto NodeJS, ma anche un particolare file cdk.json che vedremo tra poco.
In questo articolo ci concentreremo in particolare sulle cartelle “bin” e “lib” in quanto qui andremo a definire i servizi AWS che vogliamo creare.
Non tratteremo l’argomento dei test in questo articolo, quindi ci concentreremo sulle attività di codifica e deploy dell’infrastruttura.
Partendo dal file “cdk.json”, qui il campo di interesse è il cosiddetto “context”. Al suo interno definiamo un contesto per ogni ambiente in cui vogliamo effettuare un deploy, nel nostro caso li abbiamo chiamati “dev” e “prod”. Qui definiamo quante più variabili ci possono servire, tenendo conto che se rendiamo il file troppo complesso, risulterà anche più difficile da leggere e da mantenere.
Definizione della struttura
Abbiamo individuato come buona prassi, quella di definire una struttura come la seguente, andando poi a personalizzare l’oggetto “stacks” in base alle necessità:

Nella cartella “bin” troviamo un unico file, che è l’entry point del progetto. Il nome del vostro file dipenderà dal nome della cartella dentro la quale avete eseguito il comando di init in precedenza. Di seguito uno snippet del file, senza gli import dei vari pacchetti, e con la definizione di un solo stack, per brevità.

Dato che ogni costrutto CDK deve essere istanziato in un determinato scope, qui troviamo l’inizializzazione di un oggetto “App” che farà da contenitore di tutti gli stack che andremo ad istanziare. I vari servizi che andremo a definire, invece, saranno realizzati nello scope del rispettivo stack di appartenenza.
Successivamente definiamo un oggetto “builConfig”, che contiene tutte le variabili d’ambiente del deploy che vogliamo eseguire. Il tipo di oggetto “BuildConfig” è definito nel file “/lib/common/build-config.ts”. In pratica è un’interfaccia che corrisponde 1:1 ai campi presenti nell’oggetto context del file “cdk.json”. In questo modo la costante “buildConfig” conterrà tutte le variabili d’ambiente del deploy che stiamo effettuando, e le avremo disponibili negli stack in cui passiamo tale oggetto.
Creiamo anche la costante “envDetails” che viene passata ad ogni stack istanziato, per fornire le informazioni su che account e regione AWS tale stack sarà creato.
La costante “prefix” invece è una pura comodità per facilitare la nomenclatura delle risorse, in modo da avere uno standard unico in tutto il progetto.
Arrivando alla dichiarazione dello stack, così come per i costrutti che rappresentano i servizi, il costruttore si aspetta:
- scope: che come detto per gli stack è l’App;
- id: un identificativo derivante dalla dipendenza da CloudFormation, che serve a garantire l’unicità della risorsa durante il deploy;
- proprietà: queste dipendono in numero e tipo da come abbiamo definito lo stack, quindi in questo caso ad esempio viene passato l’oggetto “buildConfig”, ma potremmo passare anche interi stack ad altri stack, creando così delle dipendenze;
Infine definiamo la funzione “addTagsToStack()” che serve per aggiungere dei tag allo stack CloudFormation che verrà creato. Dato che i costrutti che gli appartengono ereditano tali tag, ci troveremo anche i servizi creati taggati in questo modo e ciò faciliterà la manutenzione dell’infrastruttura e l’individuazione delle risorse create con IaC oppure no. Ovviamente tali tag possono essere aggiunti e modificati in base alle necessità.
Passiamo ora alla cartella “lib”, che contiene tutte le dichiarazioni degli stack. Queste seguono la seguente struttura:

Ogni stack è una classe TypeScript che estendiamo per definire le proprietà di interesse. Tutte le proprietà che vogliamo esporre agli stack che importeranno questo stesso stack, le dichiariamo come “public” e saranno accessibili come campi dell’oggetto, quindi ad esempio “networkStack.vpc” oppure “networkStack.privateSubnets”.
Le definizioni di questi campi, e tutti i servizi che appartengono a questo stack, li gestiamo all’interno del costruttore.
Partendo in ordine alfabetico, vediamo i file della cartella “lib”.
La documentazione dei costrutti è disponibile al link https://docs.aws.amazon.com/cdk/api/v2/docs/aws-construct-library.html. Unico appunto, nel caso si arrivi alla documentazione tramite link esterni (esempio Stack Overflow), fare attenzione a controllare di essere nella versione #2 di CDK, visto che è la più aggiornata.
Backup
Qui creiamo una chiave KMS per criptare i backup, decidendo la “retentionPolicy” in base all’ambiente in cui siamo. La chiave poi la passiamo alla vault che andiamo a creare, che sarà il raccoglitore dei backup.
La frequenza con cui vengono realizzati i backup deriva dalle regole del piano.
Nell’esempio prevediamo una regola giornaliera con retention 7 giorni, una regola settimanale con retention 3 settimane, ed una regola mensile con retention 3 mesi.
La selezione di quali risorse sono comprese in questo piano, avviene tramite tag, in particolare, se ipotizziamo di essere in ambiente “dev”, il tag che verrà considerato valido in questo caso sarà con chiave “aws-backup-active-dev” e valore “true”.

CloudFront
Qui creiamo un bucket S3 che useremo per salvare i file ad esempio di una Single Page Application (che potrebbe essere realizzata in Angular) che verrà distribuita dalla distribuzione CloudFront. In particolare il bucket sarà privato, ed i contenuti saranno accessibili dal web solo tramite la CDN, ciò è reso possibile definendo il “defaultRootObject” che cerca un file “index.html” nella root del bucket.
Per rendere il sito più sicuro agganciamo un WAF, il servizio di firewall di AWS, che essendo un servizio globale sarà deployato sulla regione Nord Virginia. Per recuperare l’arn in maniera automatica, utilizziamo l’oggetto “parameterReader” definito nella cartella “common” che eseguirà una chiamata API.

EC2
In questo progetto di esempio, il servizio EC2 lo utilizziamo solo per la creazione di un’istanza ponte per poterci collegare alle risorse che saranno in sottoreti private, in particolare il database RDS. Nel costrutto EC2 decidiamo il tipo di istanza da utilizzare, l’AMI (quindi il sistema operativo), la quantità di storage, la posizione nella rete VPC, ed il security group che definisce le regole di accesso a questa istanza.
Come accortezza, verificare che l’AMI scelta sia disponibile nella regione di deploy, e che la chiave PEM sia già stata creata sulla console AWS. Per comodità successivamente agganciamo un Elastic IP per avere un IP pubblico statico a cui connettersi.

ECS
Questo è probabilmente il file che contiene più definizioni di risorse.
Nella prima parte definiamo il bilanciatore come pubblico, e creiamo un listener HTTPS su porta 443. Il listener è unico perché i target group sono differenziati tramite “host-header” nelle regole del listener. Il traffico sarà quindi in HTTPS dal bilanciatore verso internet, mentre in HTTP dal bilanciatore verso i servizi ECS.
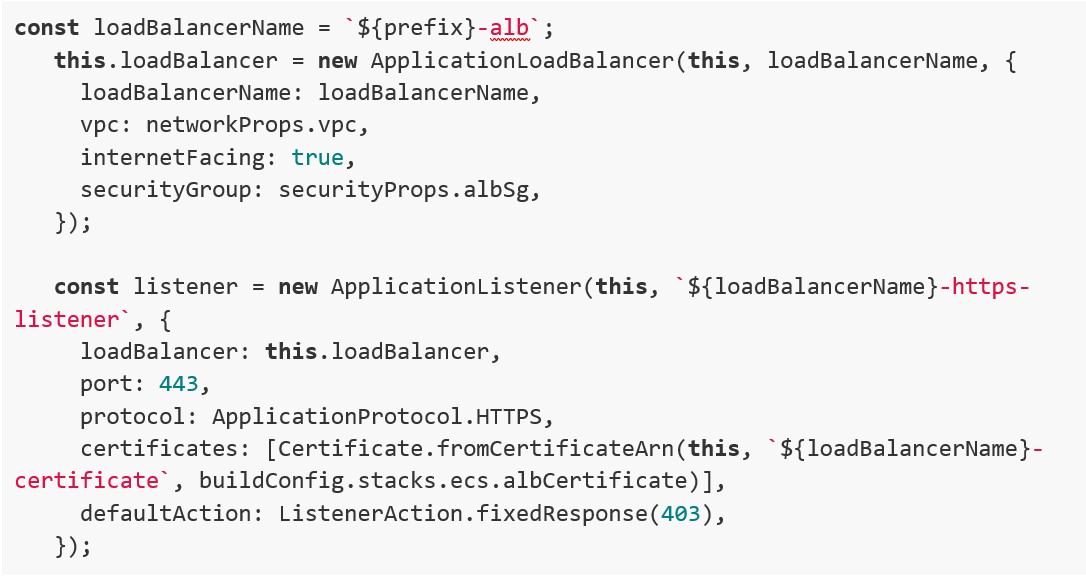
Nella seconda parte andiamo a definire il cluster ECS con i rispettivi servizi e task.
Per facilitare la configurazione, cicliamo sugli oggetti “buildConfig.stacks.ecs.services“ definiti in “cdk.json”. Questo è uno dei vantaggi maggiori di un approccio IaC, in quanto con un minimo sforzo, possiamo replicare la configurazione per tutti i servizi eliminando gli errori umani che potrebbero verificarsi eseguendo le operazioni da console o definendole una ad una. Per ogni servizio ECS è previsto un Log Group, un repository ECR ed il proprio Task Definition.
Come detto, le configurazioni principali vengono prese dal “cdk.json” quindi non è necessario modificare il codice a meno di cambiamenti strutturali.
Network
Lo stack Network prevede la creazione della rete VPC, ed all’interno due sottoreti private e due pubbliche. I range di IP e l’AZ da utilizzare sono definiti sul “cdk.json” quindi anche qui si può evitare di modificare il codice, trovandosi tutte le risorse nominate correttamente in base alle configurazioni.

RDS
Per il database il costrutto dipende dal tipo di engine scelto (esempio MySQL o PostgreSQL) e dalla scelta tra istanza RDS o cluster Aurora, quindi alcune modifiche lato codice sono possibili se si vogliono cambiare queste configurazioni. In questo caso creiamo un’istanza singola di RDS MySQL, con autoscaling dello storage definito tramite parametri del “cdk.json”. Da notare come vengono disabilitati i backup automatici di RDS impostando “backupRetention: Duration.days(0)” perché aggiungiamo il tag apposito che abbiamo previsto per la selezione di AWS Backup, in modo da non avere un costo doppio per lo storage dei backup stessi.

Security
Per abitudine raccogliamo le definizioni dei Security Group in un unico stack, per prevenire dipendenze circolari nel codice. Infatti è buona prassi utilizzare nelle regole gli ID dei Security Group dei servizi da cui vogliamo abilitare le connessioni, ed è quindi più comodo e semplice da mantenerli configurarli in un unico file.
Qui ad esempio abilitiamo le richieste verso il DB solo dai servizi ECS e dall’istanza EC2 ponte.

WAF
Il Web Application Firewall è un servizio che può essere agganciato sia a CloudFront che ad un Application Load Balancer, in base a se viene deployato a livello globale o sulla regione dell’ALB. Viene previsto un IP set per avere delle sorgenti in whitelist, e poi delle regole gestite da AWS che coprono casi d’uso tipici come, ad esempio, un attacco di SQL Injection.
Viene salvato un parametro su SSM con l’arn del WAF appena creato, che verrà poi richiamato dalla funzione “parameterReader” nel modulo di CloudFront descritto in precedenza.
Essendo da deployare a livello globale, lo stack dedicato al WAF dovrà essere in Nord Virginia, quindi c’è da fare attenzione ad eseguire il bootstrap di CDK anche in tale regione.

Arrivati al momento del deploy, vengono previsti degli script npm che facilitano l’operazione in modo da non dover ricordare la sintassi completa:
- “cdk-diff-dev”: “cdk context –clear && cdk diff $npm_config_stack -c config=dev –profile PROFILE_NAME”,
- “cdk-deploy-dev”: “cdk context –clear && cdk deploy $npm_config_stack -c config=dev –profile PROFILE_NAME”,
- “cdk-destroy-dev”: “cdk destroy $npm_config_stack -c config=dev –profile PROFILE_NAME”,
Quindi ad esempio per eseguire il deploy di un singolo stack in ambiente dev il comando da eseguire sarebbe: “npm run cdk-deploy-dev –stack STACK_NAME”.
Prendendo come esempio lo stack “ec2” che ha come parametri del costruttore anche gli stack “network” e “security”, CDK vedrà la dipendenza e li eseguirà prima dello stack “ec2” in modo da trovare pronti tutti i parametri necessari.
I principali vantaggi
Come avete potuto capire dall’esempio precedente un approccio di gestione architetturale tramite Infrastructure As Code permette di creare, controllare, aggiornare e gestire via codice un’infrastruttura rendendo programmabile quello che tipicamente veniva svolto manualmente. Alcuni dei numerosi vantaggi derivanti sono:
- Flessibilità
- Chiarezza sulle operazioni svolte
- Maggiore controllo
- Sicurezza
- Replicabilità
- Riduzione degli errori
- Documentazione sempre aggiornata
Tutto ciò però è possibile con competenze trasversali che vanno da aspetti sistemistici e infrastrutturali fino allo sviluppo software che, grazie all’approccio IaC, sarà sempre più integrato con gli applicativi sviluppati.
Per riuscire a trarne il massimo vantaggio, le organizzazioni devono iniziare a pensare alla gestione dei sistemi informativi come servizi in continua evoluzione e creare team estesi composti da tecnici, persone di business interne e partner in grado di evolvere e seguire il mercato con la stessa velocità dell’evoluzione tecnologica spinta ancora di più dai servizi cloud.
Se vuoi condividere la tua esperienza su questo ambito e le tue opinioni usa la funzione commenti!
Questo è il secondo articolo della serie a cui stiamo lavorando per trattare vari argomenti legati al mondo AWS ed in particolare sugli approcci di Infrastructure As Code.
Contattateci all’indirizzo hello@zero12.it, per richiedere degli articoli o per chiederci di trattare argomenti specifici… oppure seguite i nostri canali social per restare informati sulle prossime pubblicazioni.
Ciao 🙂

Alessandro Dindinelli
AWS Specialist zero12 – Var Group Company



Lascia un Commento
Vuoi partecipare alla discussione?Sentitevi liberi di contribuire!